August 13, 2007
Intelligent Optimization – An Introduction
This page is obsolete. Current versions of AmiBroker feature built-in non-exhaustive, smart multithreaded optimizer and walk-forward engine.
The Objectives of an Intelligent Optimizer should include the ability to:
- Optimize systems that would take too much time or would otherwise not be feasible using an Exhaustive Search approach.
- Optimize systems based on any user derived combination and/or relationship of the performance metrics provided as a result of the AmiBroker optimization process including those that users develop using the custom back tester and it should allow users to define Goals and Constraints that help direct optimization.
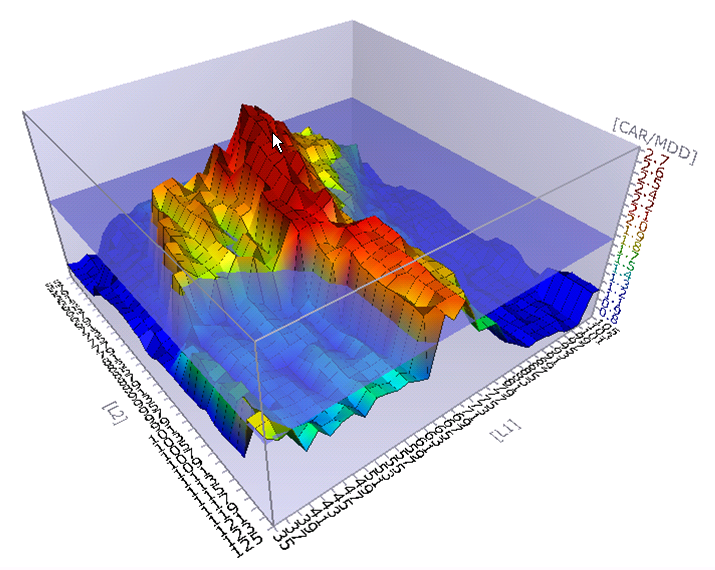
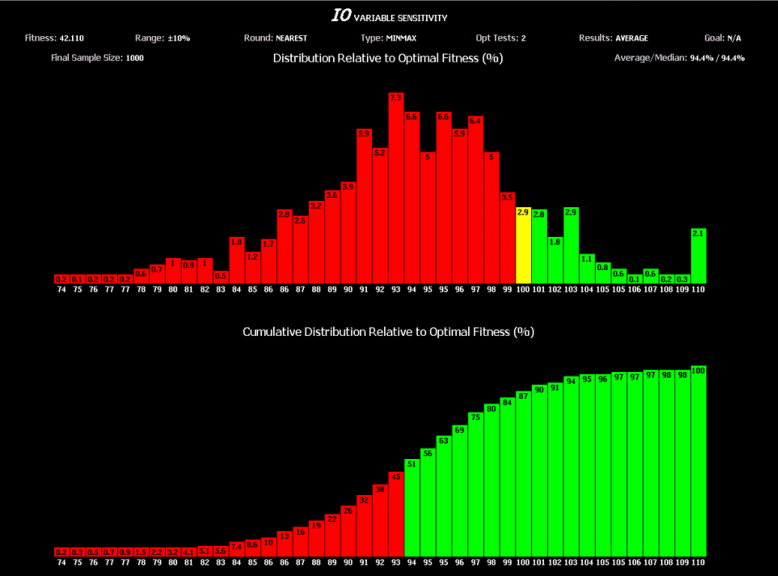
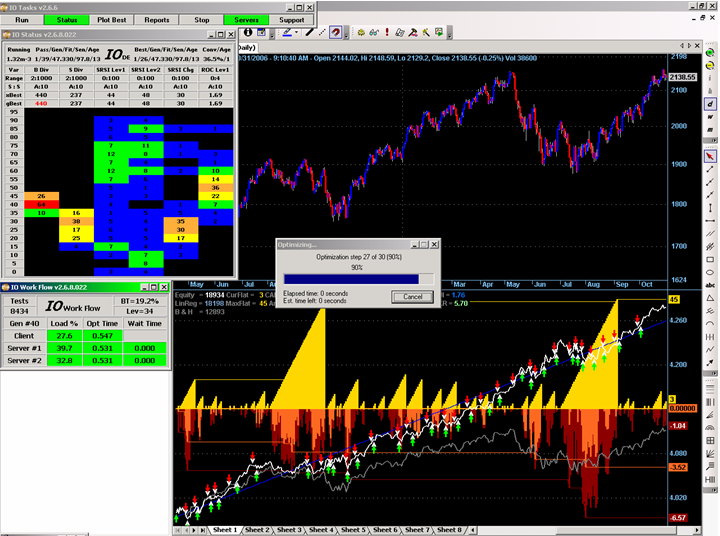
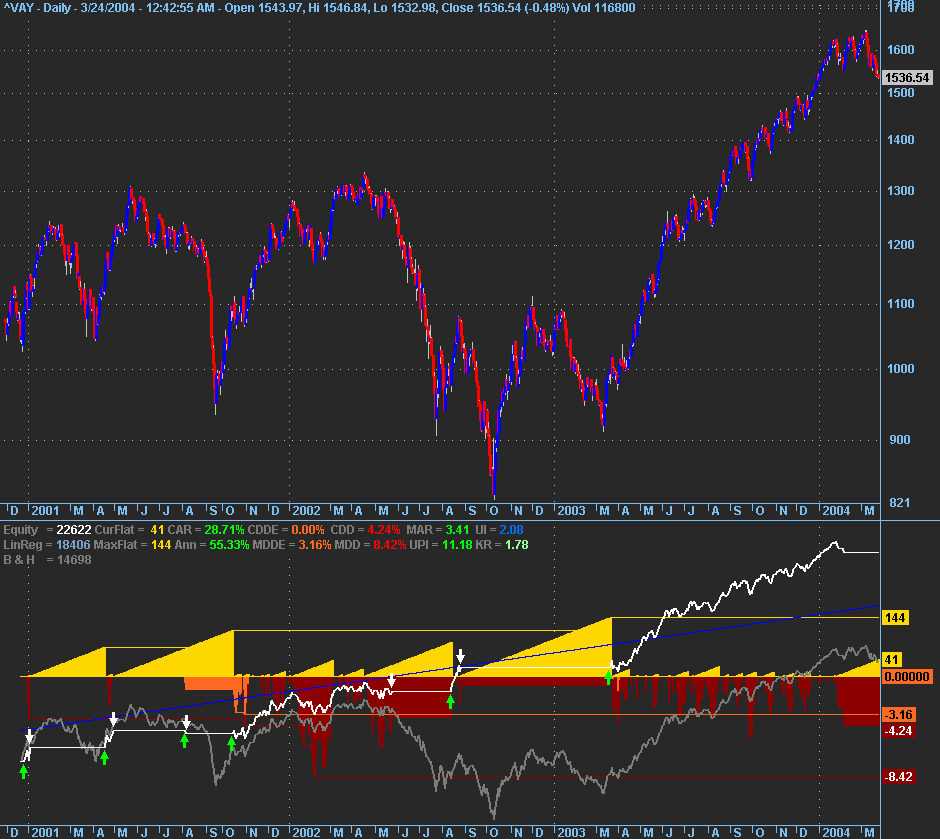
- Perform a sensitivity analysis of the variables that have been optimized and utilize parameter sensitivity as a means of directing the optimization process towards a more robust set of parameters.
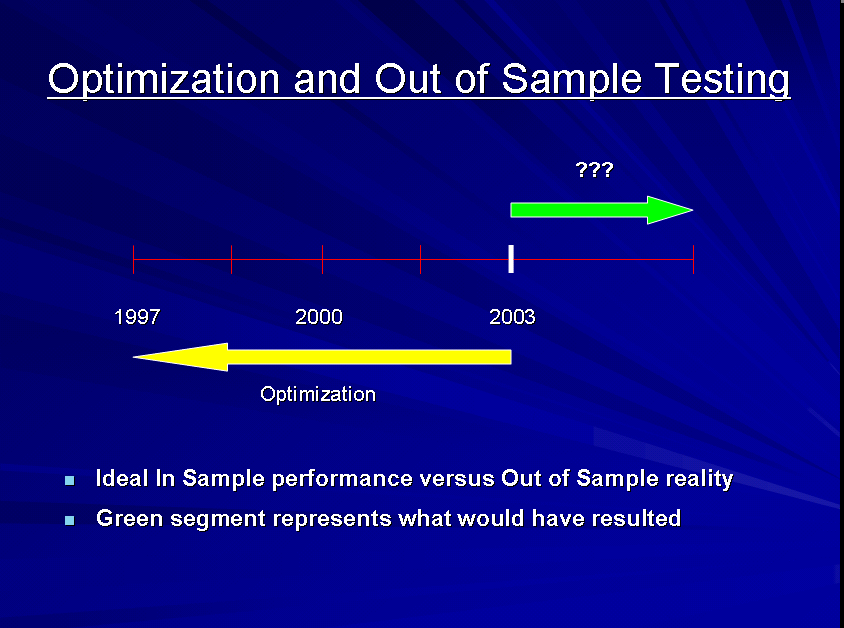
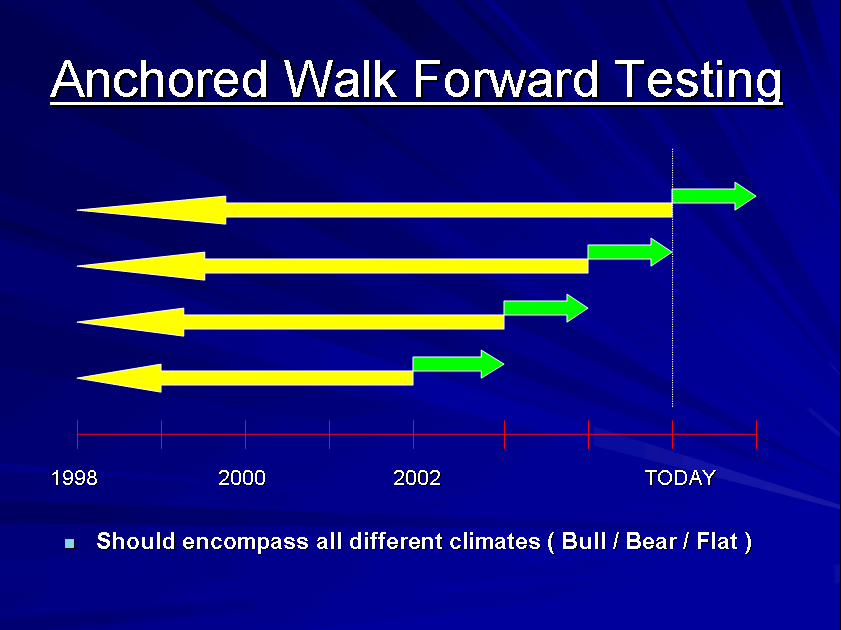
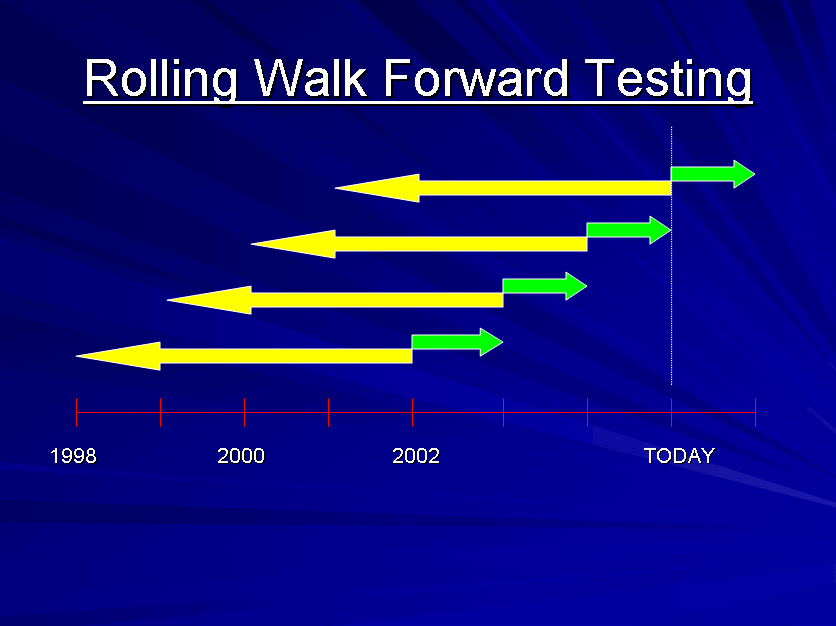
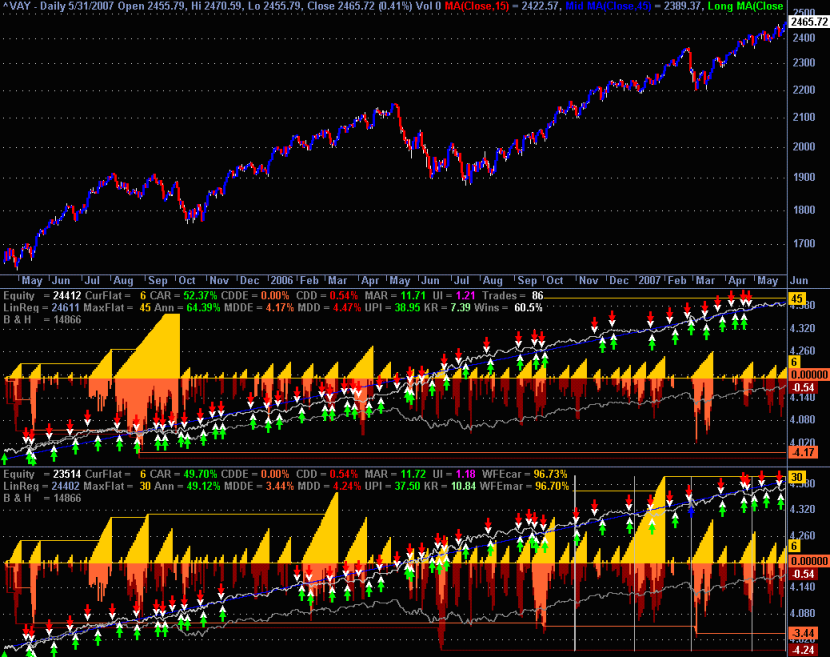
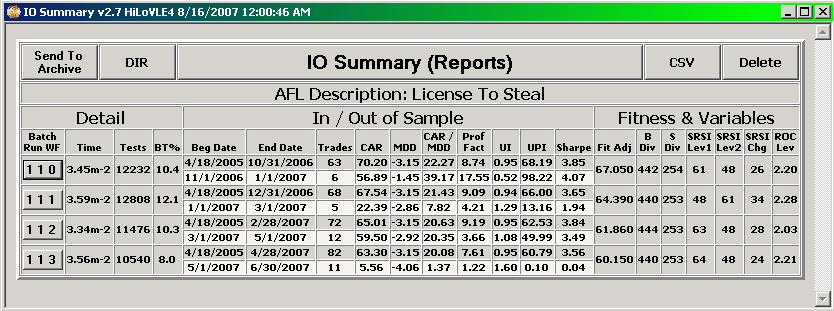
- Perform automated out of sample and walk forward testing i.e. repeated cycles of optimization of in sample data followed by back testing of out of sample data using either a front anchored or rolling window.
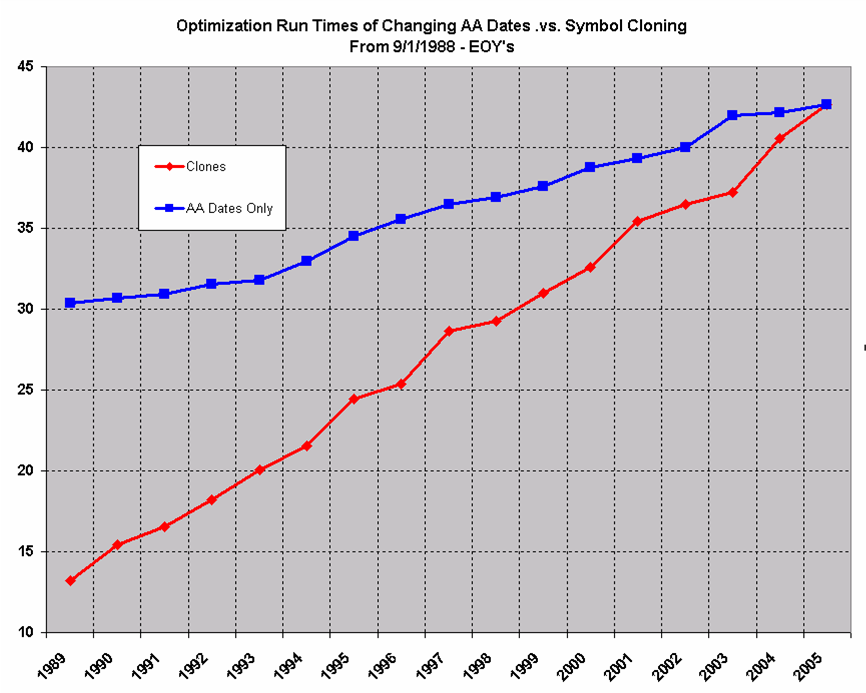
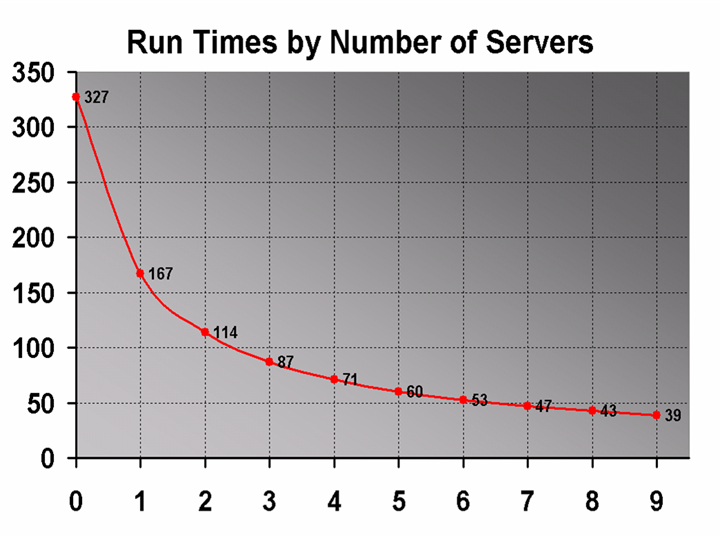
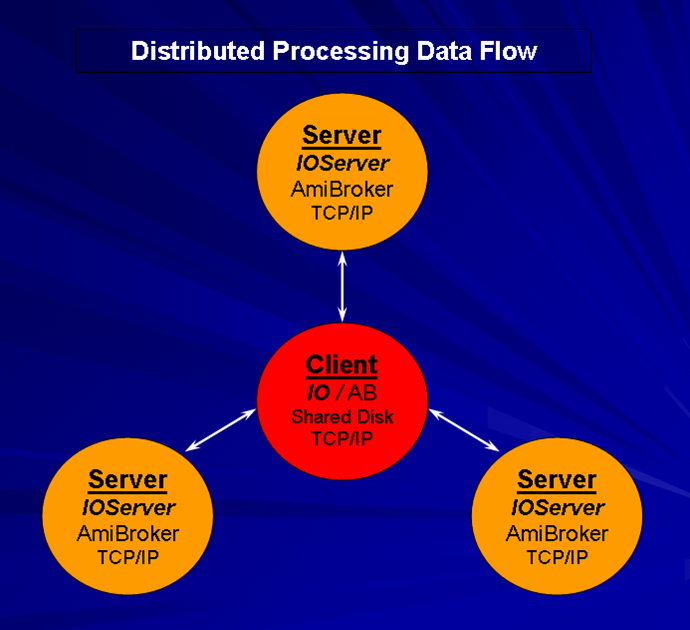
- Utilize distributed computing i.e. multiple machines to spread the optimization load over, thereby facilitating significantly faster run times.
- Utilize the full capabilities of an Intelligent Optimizer even when the decision is to strictly use AmiBroker’s Exhaustive Search optimization engine.
- Set up and solve more advanced problems not initially thought to be in the realm of optimization such as system generation via automated rule creation, selection and combination; pattern recognition and data mining.
Besides having the above functionality … It should be Easy to Use …
It should be noted that if your AFL’s use constants instead of optimizable parameters that the values of those “constants” in many situations originated by someone else optimizing something manually or otherwise at some other point in time and as such only appear to be constants. In addition as constants they have a tendency to hide how sensitive they are and as a result how robust or not the corresponding system they are part of is.
A shareware version of IO with full documentation can be found in the AmiBroker Files Section …
http://groups.yahoo.com/group/amibroker/files/IO.zip
 Filed by Fred at 5:54 am under Intelligent Optimization
Filed by Fred at 5:54 am under Intelligent Optimization
Comments Off on Intelligent Optimization – An Introduction